

Improve your SQL skills X2 in 5 minutes
SQL for managers is an underrated skill

Don’t stop your SQL journey with Joins
I divided the SQL knowledge into 6 stages. I’m not an SQL expert (you can read my mistakes in ‘How I destroyed the company’s DB’) and I probably missed some stuff, so take it as a generalization:
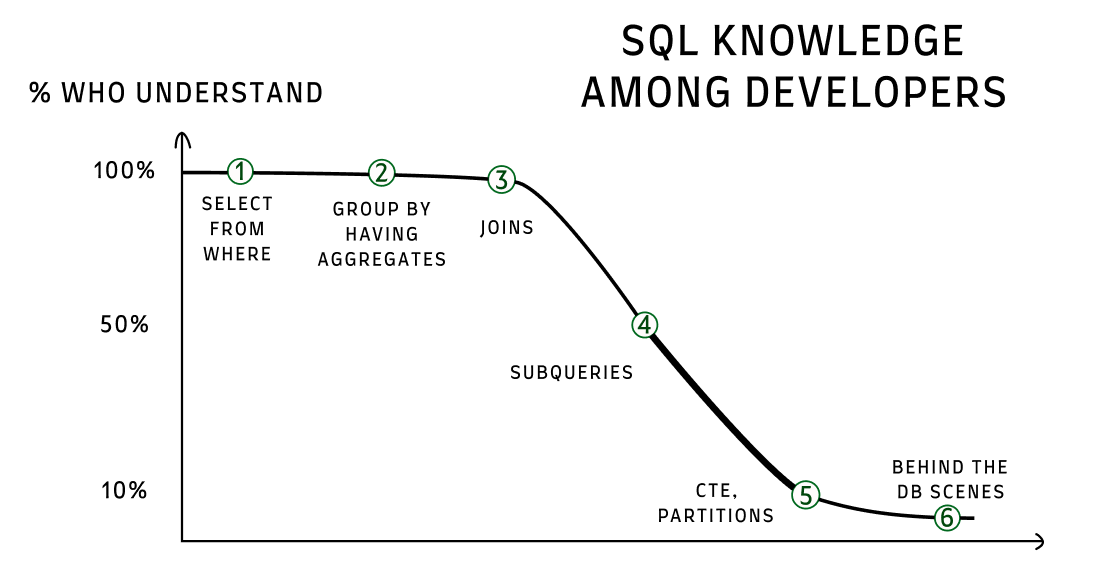
Very basic - select, from, where.
Basic - group by and having.
Beginners - joins - left/right/outer/inner/self join
Intermediate - subqueries
Most people stop after learning this stage, and it’s a shame. Stage 5 can give you a huge boost in writing complex queries!
I think it happens because in 95% of the cases, for a basic CRUD backend, it’s enough. Also, ORMs are very popular, and it’s less often that you need to write pure SQL.
Today I’m going to try and breach the gap from 4 to 5, from Intermediate to Advanced:
Advanced - working with CTEs (Common Table Expressions), window functions, and partition by command.
The material at the ‘Pro’ level is also very useful. I hope to cover it in a future article if I see interest :)
Pro:
Reading an execution plan (understanding of the ‘Explain’ command)
How indexes work (don’t just ‘CREATE INDEX’ on every column)
A deeper understanding of how the DB works (like working with the buffer_cache)
But before that:
Why do YOU need to know SQL
If you are subscribed to this newsletter, most likely you are a manager or want to become one. If you think that your SQL days are behind you - you are 100% wrong.
Writing SQL queries is one of the most useful tools a manager can have, for 3 main reasons:
You’ll be able to answer business questions. This skill can be super valuable for your connections with people from the commercial side (and PMs).
Most technical designs start with data. While you don’t need a high level of query-writing to create and understand ERDs, it can still help you to get a sense of the correct situation and the DB, and how things are connected.
The effort/benefit ratio is huge! SQL is easy to master. It can be your ‘Ace’ skill, being the go-to person for complex questions/queries.
Finally, let’s write some SQL!
I’m going to assume you are familiar with basic commands, joins, and subqueries. If not, you can refresh your memory here.
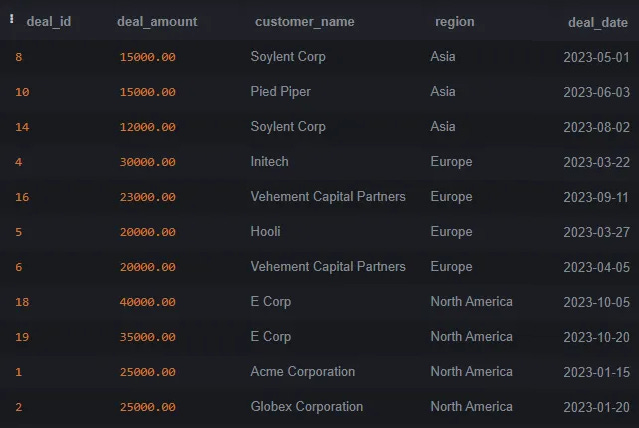
The examples are going to be based on a single table with 5 columns, with simplified types (copy code from here):

The table represents customer deals across different regions.
If you want to follow along (highly recommended!), you can do so at https://sqliteonline.com/.
We are going to need just 20 rows:

Let’s start with a short subquery refresher.
Select the biggest deal in each region
If you want some practice for interviews, this is a good place to try it yourself first :)
The naive solution:

What’s the problem with that?
The subquery is referencing a column from the outer query (d1.region). This dependency typically requires the subquery to be executed once for each row in the outer table, which can be very slow.
How can we solve it?
We can make a better subquery, but I want to introduce you to CTE - Common Table Expression.
A CTE is a temporary table that you can refer to within your SQL statement. It would look like this:

CTEs are defined using the WITH clause, followed by the CTE name, and then the query that produces the CTE. After you define it, you can select from the CTE as if it were a regular table in your database.
Why is it so useful? I can do the same with a proper subquery.
Yes, you can. CTEs do not give you a new capability (unlike the next section!), they just help you write better queries:
When using CTEs, you cannot fall into the correlated subquery trap, it forces you to think of the correct way to solve the problem.
It improves the readability of your queries.
→→→→ Here it gets interesting ←←←←
Let’s make it a bit harder:
Select the top 3 deals in each region.
Good luck doing it in an efficient way without PARTITION BY.
This is how you can use them:

And we got….. 11 deals 🤔
We’ll understand why in a moment.
Wait… What are those rank / over / partition by commands?
Let’s break it down.
RANK()is a window function. Window functions allow us to perform calculations across a set of rows that are related to the current row.To create that related set of rows we use the
PARTITION BYkeyword, which divides the dataset into groups.The
ORDER BYcommand allows us to order the rows inside each group.
For instance, RANK() OVER (PARTITION BY region) assigns a rank within each region, with the rows in each region being treated as a separate group. While "partition by" groups the data, the "window function" (like RANK) performs the calculation across these groups.
Types of Window Functions
There are 3 main types:
Ranking functions
Aggregate functions
Positional functions
(there are also cumulative distribution functions, which I’m going to skip so I’ll not lose you, the brave readers who reached this part 😂)
1. Ranking Window Functions:
Similar to what we’ve seen, they rank the rows in each partition. The main ranking functions are:
ROW_NUMBER() -assigns sequential numbers to rowsRANK() -assigns sequential numbers to rows, with the same number for ties (here’s the answer to the previous query’s results!)DENSE_RANK() -assigns sequential numbers to rows, with the same number for ties, and without compensating for the ties in the next rows.
A short example to illustrate the difference:

And the results:

This can be dangerous if not accounted for. For example, if your question is “What are the 5 biggest deals in each region”, you need to decide which of the answers you want:
ROW_NUMBER - will give the top 5, but will miss the 6th one that is tied to the 5th.
RANK - will give you 6 results, accounting for the tie for the 5th place.
DENSE_RANK - will give you 7 results, for any deals that have a deal_amount in the top 5 amounts.
Let’s move to the simpler window functions - aggregations.
2. Aggregation Window Functions
Very similar to GROUP BY aggregations, but with a huge advantage - you can keep the full data for each row!
You can use all the familiar ones - SUM(), AVG(), MAX(), and so on.
Let’s solve this question:
For each deal, select the % that the deal represents in its region.
Try it out!

And the results:

3. Positional Window Functions
These functions return a single value from a particular row in each window frame. For example:
LEAD(): Returns a value from a row that follows the current row within the partition.LAG(): Returns a value from a row that precedes the current row within the partition.FIRST_VALUE(): Returns the first value in the partition.LAST_VALUE(): Returns the last value in the partition.
Let’s see a usage example:
For each deal, calculate the change in deal amount from the previous deal by the same customer in the same region.
This will let you see the ‘direction’ of the relationship with the customer - whether the deals are increasing or decreasing.

The results will look like this:

Final words
Phew, that was quite a lot to take in!
SQL has a warm place in my heart. I feel that it is like riddles - you don’t need to google anything, there are no packages to install or weird voodoo. You know all the parameters of the problem, and you need to find the best way to solve it.
The examples here were very simple - CTEs and window functions can help you create super complex queries, for various scenarios.
This is one I wrote a few months ago, for a real use case, 4 CTEs and a couple of partitions:

(Not always complex solutions are needed, you should aim to keep things as simple as possible. Zach Wilson fromEcZachly Data Engineering Newsletter wrote a great article about how a 3-table DB got him to $1M in revenue)
What I enjoyed reading this week:
Getting Laid Off - Good Things Take Time - first post by Kevin Naughton Jr., welcome to substack!
The traits we look for in (product) engineers at PostHog by Ian Vanagas
The making of a senior engineer by Jordan Cutler and Addy Osmani
Final final words: I wish I could write SQL all day long 😂
Can you EXPLAIN which part of the post took the longest to write? Just kidding
You put explain and indexing in the Pro section. I reckon that the target group is managers - for engineers, that is something we required really early on to make sure that they think about the performance.
Great article - Thanks for writing it!
What a great post!