



How a 3rd Party API Can Ruin Your Weekend
Lessons from my longest production crisis

Last May, I experienced the toughest production incident of my career. For 2 weeks, the operations of the whole company were impacted, and there was a huge pressure on my team.
Today’s article is going to be a bit more technical. I’m going to share:
What went wrong
How we solved it
How can you avoid a similar incident
The lessons you can learn from it
Background
In the backend, we have a few microservices (written in Python, communication between them with GRPC), and an event system based on GCP’s PubSub.
There is a single (critical) microservice, that depends on a 3rd party API. When a relevant event is published, the service calls the API, processes the response, and acknowledges the event.
This is how it looks in a normal flow:
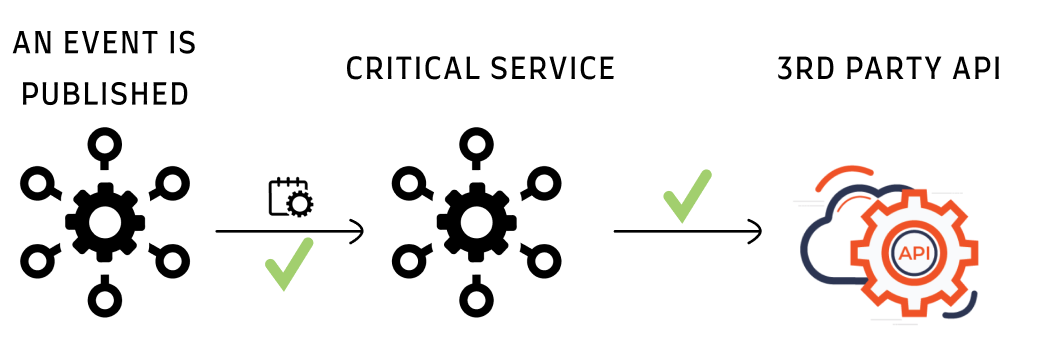
What caused the incident
One day we started to get 429 response errors from the API. This caused the processing of the events to fail. The handling of the event is not required to be real-time, and a few minutes delay is acceptable. In this case, it took hours until we processed the events, which had a severe effect on the flow of our operations.
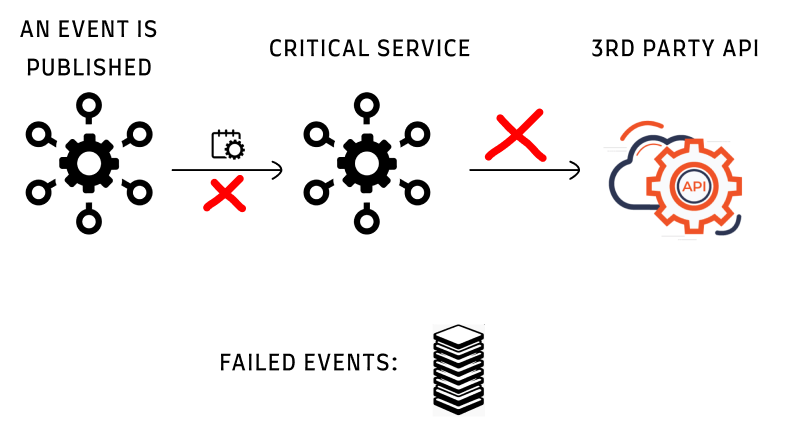
This is how a 429 response looks like:
HTTP/1.1 429 Too Many Requests
Content-Type: text/html
X-RateLimit-Limit: 100
X-RateLimit-Remaining: 0
X-RateLimit-Reset: 1630123456
Content-Length: 1234The API had a limitation (just for the example - 100 requests a minute), which we breached for the first time. So all extra requests were dropped.
To understand more deeply about rate-limiting, I suggest this article by Neo () :

Dealing with the aftermath
Initial response
Up until the 429 error, the graph of events over time looked like this:

We had small peaks of events, that were quickly processed.
Now, even with the 5 retries with a backoff policy for each event, we were in deep shit. We had thousands of failed events, and rerunning them took time (as in each rerun some events were still not processed).
It went like this:
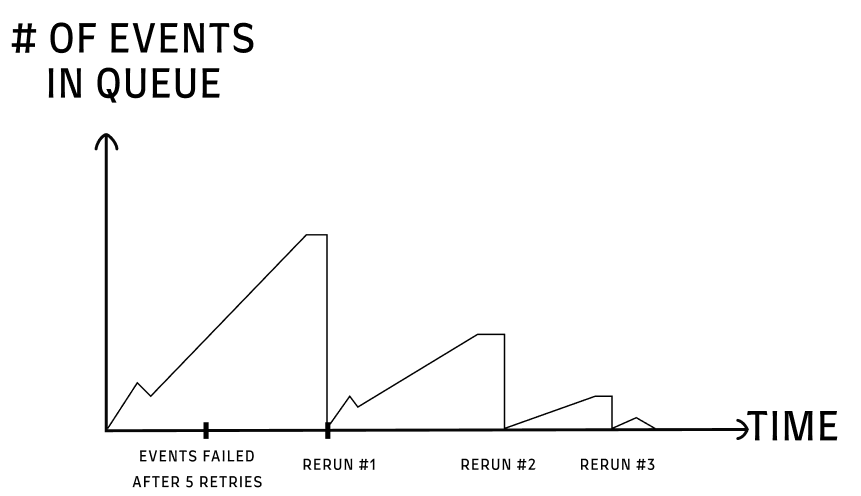
This required a manual rerun. I felt it was such a ‘demeaning’ task, and didn’t want my people to be frustrated.
We could have automated the reruns, but I decided against it for 2 reasons:
I assumed we’d find a fix quickly (a few days at most)
I was afraid to risk the situation further. Already the big delays caused some other problems, and after each rerun, we had to do some sanity checks.
Trying for a workaround
What does a developer do when reaching an API limit?

Look for workarounds…
We assumed the rate-limiting would be per API token. So we created multiple pods with different API keys, and load-balanced the handling of events between them.
It didn’t work. We thought maybe it was per user, so we generated new API keys from different users.
That didn’t work either…
Turns out the rate-limiting was for our whole project. To my defense, this was not written in the documentation (and we pay a substantial sum for that API, so the assumption that there is no hard limit was not that far-fetched).
The Fix
After wasting time on the failed workaround, we decided to go in 3 parallel directions:
Optimizing the calls to the service
When trying to debug which events were the most common, we found 2 things:
With a small change of logic, we could reduce the amount of events by 50%.
Some calls to the 3rd party API can be batched (5 calls → 1 call)
Implementing suitable response to 429 errors
In the HTTP response, the X-RateLimit-Reset gives us the time when we could use the API again. Until that time, any calls will fail. So instead of just retrying, once a call got the 429 response, the service awaited until reaching the X-RateLimit-Reset, and only then retried.
This still caused a delay (as all the events waited in the queue until the service could process them), but at least there were no failures (and no need for manual retries anymore 🎉).
For this we involved the Architects’ team, to help us ASAP (we are a small startup, and they are the most experienced engineers).
Increasing our limits with the 3rd party API provider
We understood that even with our optimizations, we would still need a higher limit for our peak hours.
How Could It Have Been Avoided?
Dependency on a 3rd party 🔗
This one was tricky to avoid. There was no rate-limiting specified in the documentation, and even when we talked with the company, they mentioned they could change the limit at any time and they couldn’t say what it would be.
This raises the question if we can count on such a service, and that’s a business decision even more than it’s a technical one.
Load testing 🏋️
This one is 100% on me.
People suggested doing a proper load test before the start of the growing season (as we had a lot of changes from the previous one, including increased dependency on that cursed 3rd party API).
Doing a proper load test would have taken us a couple of weeks, as we didn’t have the infrastructure to simulate 100% of the real scenarios.
I’ve had a bad experience with load tests. As you are doing a simulation, Merphy’s law is that the places you deviated from production will be the ones that actually break later on…
Lessons Learned
Phew, that was a long one :)
❌ Distribution of the load
The incident highlighted my tendency to ‘shield’ the team. Only after a full week, we established an on-call rotation. Until then, I was rerunning the events myself until 2 AM each day.
The absurd is when you try to shield the team from ‘demeaning’ or ‘tedious’ work, you send the message that you don’t trust them. That only YOU can be counted on.
❌ Depending on manual work
My decision to not automate the manual rerun of failed events was wrong. I assumed it would be a few days, and the risk of automating was not worth it.
✔️ Involving cross-team functions
The Architects and DevOps team were a game changer. They were willing to go hands-on and work around the clock to help.
In cases like this, when you are trying multiple solutions at the same time - having experienced outside help is crucial.
Summary
👀 Carefully research any 3rd party API you depend upon
🤝 Share the load with your team (even the annoying stuff)
🔀 When you are not sure what’ll work - go in multiple directions in parallel (even at the risk of wasting time)
I went back to the format people seemed to like previously, sharing real stories and what I learned from them. In retrospect, some of our mistakes may sound stupid - I hope the article will help you avoid similar ones :)
Incidents are a great way to learn and improve! Sounds like manual remediation for multiple days was a miss but I am sure it left a mark on you :)
Thanks for sharing your story. We have a 3rd party api to draw a chart in an email. So when the schedule task sent the email, emails went with no chart. Of course this didn’t block operations but the business value was lost. The logs reported 429 failure code too.
I wrote directly to the api provider to know their rate limit. I would have even called them. 😀
In another similar incident, api provider black-listed us and that was some fun.